Natural language processing
What motivates us
Natural language processing (NLP) is at the epicenter of many recent advances in AI, including large language models such as GPT-3 and BERT. But while these methods work amazingly well for analyzing general-purpose text, they are substantially less reliable when they need to analyze the more specialized and lower-volume text present for many specialized domains within Bosch.
Our approach
For scalable NLP in Bosch’s heterogenous industrial context, a key challenge we address with our research is NLP in low-resource settings, i.e., settings where only little (annotated) data is available. For this, we work on topics, such as robust input representations, transfer learning, custom deep learning models, and the creation of custom training and evaluation data.
Application
A lot of knowledge is hidden in large amounts of unstructured data available in various forms (e.g., scientific publications, web content, corporate documents, etc.). Thus, NLP is one of the fundamental technologies to enable the intelligence of various Bosch products and services, especially in terms of converting text data into knowledge, retrieving knowledge for users’ needs, and, in general, going the path from text to knowledge to value. Our techniques are useful to business units with a need to directly parse or understand large amounts of text data, or settings where one needs to understand semantic structure and meaning about the objects underlying text descriptions. Two examples are the materials science and automotive domains.
Low-resource NLP

Recent advancements in NLP benefit of huge amounts of data, e.g., in the context of large language models. However, industrial use cases for applying NLP technology do not provide large amounts of labeled training data so that out-of-the-box methods often fail when applied in specialized domains. For scalable NLP in Bosch’s heterogenous industrial context, a key challenge we address with our research is thus NLP in low-resource settings.
Use case
NLP — working with little training data and in long-tail settings
-
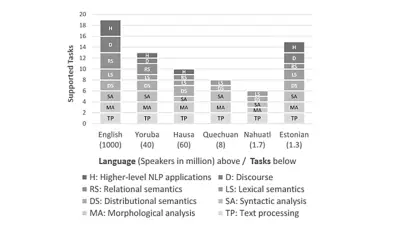
This image shows supported NLP tasks in different languages, differentiating between lower-level tasks (such as morphological or syntactic analysis) and higher-level tasks (such as relational semantics or applications).
Introduction
Industrial use cases for the application of NLP technologies often do not provide a large amount of labeled training data as the creation of annotated corpora usually requires domain expertise and is hence very costly. In long-tail settings, such as patent classification, there are many data points for some categories, but only few for other categories that may nevertheless be of interest. Out-of-the-box methods often fail in such cases.
We address these problems in our research activities with a special focus on low-resource settings, multilingual solutions and long-tail scenarios. With the aim of ethical and explainable NLP, we also perform exploratory research in the areas of uncertainty and explainable AI.
Our research
Robust Representations
We explore new ways of creating robust neural representations for text data. For instance, combining several embeddings typically improves performance in downstream tasks as different embeddings encode different information.
Transfer learning
In low-resource settings, there is only little or even no annotated data available. Thus, we aim at exploiting existing, related datasets in an optimal way by using transfer learning.
Multi-label and hierarchical classification
Our methods aim at ensuring high performance for infrequent cases.
Explainable predictions
We carefully evaluate the explanations given by systems with the aim of providing the user with meaningful feedback. For this we do not stick to existing evaluation methods but also suggest new, better-suited metrics to assess different approaches.
Example technology: meta-embedding layer
-
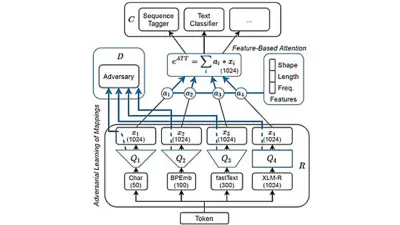
This image shows the meta-embedding layer which combines a set of input embeddings using feature-based attention and is trained with adversarial training.
References
Hedderich, M.A., Lange, L., Adel, H., Stroetgen, J., & Klakow, D. (2021). A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios. NAACL. [PDF]
Lange, L., Adel, H., Stroetgen, J., & Klakow, D. (2021). FAME: Feature-Based Adversarial Meta-Embeddings for Robust Input Representations. EMNLP. [PDF]
Lange, L., Stroetgen, J., Adel, H., & Klakow, D. (2021). To Share or not to Share: Predicting Sets of Sources for Model Transfer Learning. EMNLP. [PDF]
Pujari, S., Friedrich, A., & Stroetgen, J. (2021). A Multi-Task Approach to Neural Multi-Label Hierarchical Patent Classification using Transformers. ECIR. [PDF]
Schuff, H., Adel, H., & Vu, N.T. (2020). F1 is Not Enough! Models and Evaluation Towards User-Centered Explainable Question Answering. EMNLP. [PDF]
Robust information extraction
The Natural Language Processing task of information extraction can make knowledge hidden in textual documents available in a structured format. In our heterogeneous industrial context, scalable information extraction requires domain robustness and multilinguality.
Introduction
Today, a lot of knowledge is hidden in large amounts of unstructured data available in various forms like scientific publications, web content or corporate documents. To exploit this knowledge in downstream applications and to go the path from text to knowledge to value, robust information extraction is required to encode the knowledge in a structured manner. Most NLP systems rely on methods trained and optimized on news or web data. Making them work optimally in other domains is not straightforward. Our goal is to advance the state of the art by developing general methods that work robustly across domains, with a special focus on domains and subject areas relevant to Bosch.
Our research
Component-based research
We develop methods and models for natural language processing with the aim of providing re-usable components that either work robustly across domains or can be adapted easily.
From unstructured to structured data
We develop methods and models for knowledge base population to make knowledge hidden in unstructured text available in a machine-accessible manner.
Understand texts
We develop syntactic and semantic parsing approaches that work for many languages and domains.
Data is key
In order to ensure high-quality applications in particular domains, we also support particular use cases at Bosch by creating and releasing annotated text data sets.
-

This image gives an example for a sentence taken from a materials science publication annotated with slots indicating the anode material, the working temperature, etc.
References
Ho, V. T., Stepanova, D., Milchevski, D., Stroetgen, J., & Weikum, G. (2022). Enhancing Knowledge Bases with Quantity Facts. WWW. [PDF]
Lange, L., Adel, H., Stroetgen, J., & Klakow, D. (2022). CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain. Oxford Bioinformatics journal. [PDF]
Sineva, E., Grünewald, S., Friedrich, A., & Kuhn, J. (2021). Negation-Instance Based Evaluation of Negation Resolution. CoNLL. [PDF]
Grünewald, S., Piccirilli, P., & Friedrich, A. (2021). Coordinate Constructions in Enhanced Universal Dependencies: Analysis and Computational Modeling. EACL. [PDF]
Grünewald, S., Friedrich, A., & Kuhn, J. (2021). Applying Occam's Razor to Transformer-Based Dependency Parsing: What Works, What Doesn't, and What is Really Necessary. IWPT. [PDF]
Friedrich, A., Adel, H., Tomazic, F., Benteau, R., Hingerl, J., Marusczyk, A., & Lange, L. (2020). The SOFC-Exp Corpus and Neural Approaches to Information Extraction in the Materials Science Domain. ACL. [PDF]
Lange, L., Adel, H., & Stroetgen, J. (2020). Closing the Gap: Joint De-Identification and Concept Extraction in the Clinical Domain. ACL. [PDF]