Natural Language Processing – Sprache verstehen, Wissen nutzbar machen
Was uns antreibt
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) steht im Zentrum vieler aktueller KI-Entwicklungen – darunter auch große Sprachmodelle wie GPT-3 oder BERT. Während diese Methoden für die Analyse von allgemeinen Texten erstaunlich gut funktionieren, sind sie deutlich weniger zuverlässig, wenn es um die Analyse spezieller und textärmerer Inhalte geht, wie sie in vielen Fachgebieten bei Bosch vorkommen.
Unser Ansatz
Das Ziel ist ein skalierbares NLP im heterogenen industriellen Kontext bei Bosch. Die zentrale Herausforderung besteht in sogenannten Low-Resource-Settings – also Szenarien, in denen nur sehr wenig (annotierte) Trainingsdaten vorliegen. Dafür arbeiten wir an Themen wie: Robuste Repräsentationen für Eingabedaten
- Transfer Learning zwischen verwandten Aufgaben oder Domänen
- Anpassung von Deep-Learning-Modellen an spezifische Anforderungen
- Erstellung individueller Trainings- und Evaluationsdaten
Anwendungsfelder
Ein Großteil des verfügbaren Wissens liegt in unstrukturierten Textdaten, die in unterschiedlichen Formen vorliegen, z. B. in wissenschaftlichen Publikationen, Webseiten oder internen Dokumenten. NLP ist die Schlüsseltechnologie, um dieses Wissen zu erschließen und für Bosch-Produkte und -Services nutzbar zu machen – etwa durch:
- Wissensextraktion aus Texten
- Abrufen von Wissen entsprechend der Nutzerbedürfnisse
- Umwandlung von Text in Wissen und von Wissen in Mehrwert
Unsere Methoden sind besonders hilfreich für Geschäftsbereiche, die große Mengen an Textdaten direkt analysieren oder verstehen müssen, oder in Szenarien, in denen die semantische Struktur und Bedeutung der hinter Textbeschreibungen liegenden Objekte erfasst werden sollen. Beispiele für Einsatzbereiche sind die Materialwissenschaft und die Automobilbranche.
Low-Resource NLP

Die jüngsten Fortschritte im Natural Language Processing (NLP) basieren auf sehr großen Datenmengen, etwa beim Training großer Sprachmodelle. In der Industrie sind solche Datenbestände jedoch selten verfügbar: Annotierte Trainingsdaten fehlen oder sind aufgrund des notwendigen Fachwissens nur mit hohem Aufwand zu erstellen. Für ein skalierbares NLP im heterogenen industriellen Umfeld von Bosch entwickeln wir daher Verfahren, die auch in Low-Resource-Settings zuverlässig funktionieren.
Use Case
NLP bei geringen Datenmengen und in Long-Tail-Szenarien
-
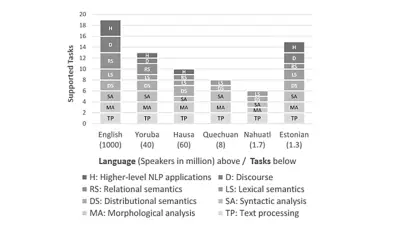
Dieses Bild zeigt unterstützte NLP-Tasks in verschiedenen Sprachen und unterscheidet zwischen niedrigeren Tasks (wie morphologische oder syntaktische Analyse) und höheren Tasks (wie relationale Semantik oder Anwendungen).
Einführung
In Long-Tail-Szenarien – etwa bei der Patentklassifikation – existieren für einige Kategorien zahlreiche Datenpunkte, während für viele andere nur sehr wenige Beispiele verfügbar sind, die dennoch geschäftlich relevant sein können. Standardverfahren stoßen in solchen Fällen häufig an ihre Grenzen.
Wir fokussieren uns daher auf:
- Low-Resource-Settings
- Mehrsprachige Lösungen
- Long-Tail-Szenarien
- Uncertainty & Explainable AI
Unsere Forschung
Robuste Repräsentationen
Wir entwickeln neue Ansätze zur Erstellung robuster neuronaler Repräsentationen für Textdaten. Zum Beispiel kombinieren wir verschiedene Embeddings, die jeweils unterschiedliche Informationen abbilden.
Transfer Learning
In datenarmen Szenarien nutzen wir verwandte Datensätze optimal aus, um robuste Modelle auf neue Aufgaben zu übertragen – auch ohne direktes Training auf Zieldaten.
Multi-Label und hierarchische Klassifikation
Unsere Methoden sind darauf ausgelegt, auch bei seltenen Fällen leistungsfähig zu sein.
Erklärbare Vorhersagen
Wir prüfen die von Systemen erzeugten Erklärungen sorgfältig, um Anwenderinnen und Anwendern nachvollziehbares Feedback zu geben. Dabei greifen wir nicht nur auf bestehende Evaluationsmethoden zurück, sondern entwickeln auch neue, besser geeignete Kennzahlen.
Beispieltechnologie: Meta-Embedding Layer
-
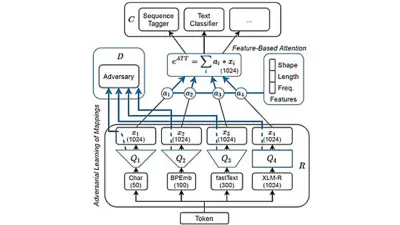
Ein Beispiel ist unser Meta-Embedding-Ansatz, der mehrere Eingabe-Embeddings kombiniert. Durch Attention-Mechanismen und adversariales Training entsteht eine besonders robuste Repräsentation für nachgelagerte Aufgaben.
Referenzen
Hedderich, M.A., Lange, L., Adel, H., Stroetgen, J., & Klakow, D. (2021). A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios. NAACL. [PDF]
Lange, L., Adel, H., Stroetgen, J., & Klakow, D. (2021). FAME: Feature-Based Adversarial Meta-Embeddings for Robust Input Representations. EMNLP. [PDF]
Lange, L., Stroetgen, J., Adel, H., & Klakow, D. (2021). To Share or not to Share: Predicting Sets of Sources for Model Transfer Learning. EMNLP. [PDF]
Pujari, S., Friedrich, A., & Stroetgen, J. (2021). A Multi-Task Approach to Neural Multi-Label Hierarchical Patent Classification using Transformers. ECIR. [PDF]
Schuff, H., Adel, H., & Vu, N.T. (2020). F1 is Not Enough! Models and Evaluation Towards User-Centered Explainable Question Answering. EMNLP. [PDF]
Robuste Informationsextraktion
Die Aufgabe der Informationsextraktion im Natural Language Processing (NLP) besteht darin, verborgenes Wissen aus Textdokumenten zu erschließen und in eine strukturierte, maschinenlesbare Form zu überführen. Damit dies im heterogenen industriellen Umfeld von Bosch in großem Maßstab gelingt, braucht es Verfahren, die domänenübergreifend robust sind und mehrsprachig eingesetzt werden können.
Einführung
Ein Großteil des Wissens steckt heute in großen Mengen unstrukturierter Daten – etwa in wissenschaftlichen Publikationen, Webinhalten oder Unternehmensdokumenten. Um dieses Wissen in nachgelagerten Anwendungen nutzbar zu machen und den Weg von Text zu Wissen zu Mehrwert zu gehen, ist eine robuste Informationsextraktion erforderlich, die Inhalte in eine strukturierte Form überführt.
Die meisten NLP-Systeme basieren auf Methoden, die auf Nachrichten- oder Webdaten trainiert und optimiert wurden. Ihre Übertragung auf andere Domänen ist jedoch nicht ohne weiteres möglich. Unser Ziel ist es daher, den Stand der Technik weiterzuentwickeln – durch allgemeine Verfahren, die domänenübergreifend robust funktionieren, mit besonderem Fokus auf Anwendungsbereiche, die für Bosch relevant sind.
Unsere Forschung
Komponentenbasierte Forschung
Wir entwickeln Methoden und Modelle für Natural Language Processing (NLP), um wiederverwendbare Komponenten bereitzustellen, die entweder robust in verschiedenen Domänen funktionieren oder sich bedarfsgerecht anpassen lassen.
Von unstrukturiert zu strukturiert
Wir entwickeln Methoden und Modelle zur Anreicherung von Wissensbasen, um verborgenes Wissen aus unstrukturierten Texten in maschinenlesbarer Form verfügbar zu machen.
Texte verstehen
Wir arbeiten an syntaktischen und semantischen Parsing-Ansätzen, die in vielen Sprachen und Domänen zuverlässig einsetzbar sind.
Daten sind entscheidend
Um hochwertige Anwendungen in Spezialgebieten zu ermöglichen, unterstützen wir konkrete Anwendungsfälle bei Bosch durch die Erstellung und Bereitstellung annotierter Textdatensätze.
-

Die Abbildung zeigt ein Beispiel aus einer Veröffentlichung der Materialwissenschaften. Der Satz ist mit Annotationen versehen, die unter anderem das Anodenmaterial, die Betriebstemperatur und weitere Merkmale kennzeichnen.
Referenzen
Ho, V. T., Stepanova, D., Milchevski, D., Stroetgen, J., & Weikum, G. (2022). Enhancing Knowledge Bases with Quantity Facts. WWW. [PDF]
Lange, L., Adel, H., Stroetgen, J., & Klakow, D. (2022). CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain. Oxford Bioinformatics journal. [PDF]
Sineva, E., Grünewald, S., Friedrich, A., & Kuhn, J. (2021). Negation-Instance Based Evaluation of Negation Resolution. CoNLL. [PDF]
Grünewald, S., Piccirilli, P., & Friedrich, A. (2021). Coordinate Constructions in Enhanced Universal Dependencies: Analysis and Computational Modeling. EACL. [PDF]
Grünewald, S., Friedrich, A., & Kuhn, J. (2021). Applying Occam's Razor to Transformer-Based Dependency Parsing: What Works, What Doesn't, and What is Really Necessary. IWPT. [PDF]
Friedrich, A., Adel, H., Tomazic, F., Benteau, R., Hingerl, J., Marusczyk, A., & Lange, L. (2020). The SOFC-Exp Corpus and Neural Approaches to Information Extraction in the Materials Science Domain. ACL. [PDF]
Lange, L., Adel, H., & Stroetgen, J. (2020). Closing the Gap: Joint De-Identification and Concept Extraction in the Clinical Domain. ACL. [PDF]