Deep Learning – Treiber von Bosch-Innovationen
Was uns antreibt
Deep Learning (DL) ist ein Teilgebiet von maschinellem Lernen, das auf mehrstufiger Datenverarbeitung in neuronalen Netzen basiert. In den vergangenen Jahren hat diese Technologie einige der spannendsten Durchbrüche in der KI ermöglicht – etwa in den Bereichen Computer Vision, Sprachverstehen und Spracherkennung. Damit ist Deep Learning ein zentraler Treiber für Bosch-Anwendungen wie automatisiertes Fahren, Robotik oder Embedded AI.
Trotz ihres Potenzials haben aktuelle Deep-Learning-Modelle auch Schwächen: Sie benötigen große Daten- und Rechenressourcen, sind im Realbetrieb oft instabil und ihre Ergebnisse schwer nachvollziehbar. Deep Learning liefert in erster Linie Vorhersagen, jedoch keine Begründung dafür, wie sie zustande kommen. Genau diese Herausforderungen motivieren uns bei Bosch, robuste, sichere und effiziente Deep-Learning-Modelle zu entwickeln, die Teil unserer kontinuierlich lernenden AIoT-Produkte sind.
Unser Ansatz
Bei Bosch treiben wir die Deep-Learning-Forschung gezielt voran, damit unsere Produkte noch intelligenter, sicherer und leistungsfähiger werden.
Wir entwickeln:
- neue Methoden für erklärbare KI und robuste Modelle
- innovative Trainingsverfahren für verschiedene Hardwaretypen
- Tools, die Deep Learning effizient in Embedded-Systemen skalieren
Dateneffizientes Lernen und generative Modelle ermöglichen es uns, Datensätze um realitätsnahe und vielfältige Szenarien zu erweitern, was den Aufwand für Datensammlung und -labeling erheblich reduziert.
Anwendungsfelder
Das breite Bosch-Produktportfolio eröffnet vielfältige Use Cases für Deep Learning. Zu unseren zentralen Fachgebieten zählen:
- Umfelderkennung für Fahrerassistenzsysteme und automatisiertes Fahren
- Robotik
- Medizintechnik
- Smarte Kamera-Lösungen
- diverse AIoT-Anwendungen
Embedded Deep Learning

Embedded Deep Learning macht modernste Wahrnehmungsmodelle für Bosch-Sensoren nutzbar – mit optimierter Effizienz auf eingebetteten KI-Plattformen.
Damit Wahrnehmungsmodelle auch auf Hardware mit begrenzten Ressourcen effizient laufen, setzen wir auf Verfahren wie Hardware-Aware Neural Architecture Search (NAS). Diese Methoden sind entscheidend für leistungsfähige KI-Produkte.
Embedded Deep Learning kommt bereits in Video-, Radar- und Ultraschallsensoren zum Einsatz – für mehr Präzision, Effizienz und Leistung. Bei Bosch arbeiten KI-, Hardware- und Domänenexpertinnen und -experten eng zusammen, um das volle Potenzial eingebetteter KI-Systeme auszuschöpfen.
Use Case
Hardware-Aware Neural Architecture Search (NAS)
-
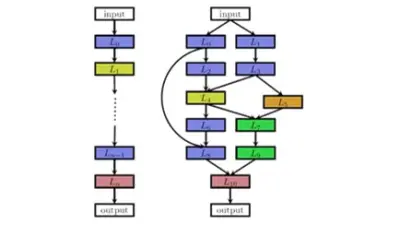
Figur 1
Einführung
KI, die das optimale Netzwerkdesign selbst entwirft – maßgeschneidert für jede Hardware. Möglich wird dies durch Algorithmen und Tools, die unsere Forschenden entwickeln und die:
- Zeit und Kosten beim KI-Training deutlich reduzieren
- hochpräzise Ergebnisse liefern
- den Rechenaufwand um ein Vielfaches senken – für geringere Hardwarekosten und mehr Energieeffizienz
Ziele, die wir mit NAS verfolgen:
- Methoden entwickeln, die aus Deep-Learning-Architekturen die maximale Leistung herausholen – abgestimmt auf ein konkretes Hardware-Budget.
- Die Praxistauglichkeit demonstrieren, etwa mit effizienten Architekturen für Videokameras oder Radarsensoren der neuesten Generation.
Unsere Forschung
Tools für NAS
Differenzierbare und anschlussfähige NAS-Methoden
Wir entwickeln modulare, wiederverwendbare Python-Tools für zahlreiche Embedded-AI-Anwendungen. Sie integrieren unsere neuesten Forschungsergebnisse und enthalten spezifische Optimierungen für relevante Hardwareplattformen.
Effizienter werden
Hardware Awareness schafft Lösungen nach Maß:
Gemeinsam mit Hardware-Expertinnen und -experten definieren wir Modelle und Kostenfunktionen, die Deep-Learning-Modelle präzise auf verschiedene Plattformen abstimmen.
Das Ergebnis: Höchste Leistung bei stark reduziertem Rechenaufwand.
Pilotprojekte: NAS in der Praxis
Unsere NAS-Tools beschleunigen die Entwicklung optimierter Netzwerkarchitekturen – ideal für neue Anwendungsfelder mit komplexen Anforderungen. Die Lösungen lassen sich nahtlos in kontinuierlich lernende Produkte integrieren.
Forschung auf Spitzenniveau
Unsere NAS-Methoden entstehen in enger Kooperation mit der Universität Freiburg. Wir entwickeln den Stand der Technik stetig weiter, veröffentlichen auf führenden internationalen Konferenzen und erproben unsere Ansätze in realen Bosch-Anwendungen – für Embedded AI auf höchstem Niveau.
-
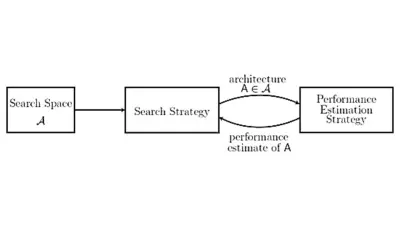
Figur 2
Referenzen
Elsken, T., Metzen, J. H., & Hutter, F. (2019). Neural architecture search: A survey. The Journal of Machine Learning Research, 20(1), 1997-2017. [PDF]
Elsken, T., Metzen, J. H., & Hutter, F. (2018). Efficient Multi-Objective Neural Architecture Search via Lamarckian Evolution. ICLR. [PDF]
Elsken, T., Zela, A., Metzen, J. H., Staffler, B., Brox, T., Valada, A., & Hutter, F. (2022). Neural Architecture Search for Dense Prediction Tasks in Computer Vision. arXiv preprint. [PDF]
Schorn, C., Elsken, T., Vogel, S., Runge, A., Guntoro, A., & Ascheid, G. (2020). Automated design of error-resilient and hardware-efficient deep neural networks. Neural Computing and Applications, 32(24), 18327-18345. [PDF]
Dateneffizienz und Unsicherheiten im DL

Daten sind entscheidend für die Leistung und Generalisierung von Deep-Learning-Modellen. Doch Einschränkungen bei der Datenerfassung führen oft dazu, dass nicht genügend Trainingsdaten für einen zuverlässigen Einsatz zur Verfügung stehen.
Darum ist Dateneffizienz im Deep Learning von zentraler Bedeutung: Sie ermöglicht es den Modellen, auch in komplexen Anwendungsfeldern zu lernen, ohne auf riesige Datenmengen angewiesen zu sein. Wir setzen vor allem auf synthetische Daten und auf Unsupervised Domain Adaptation (UDA), also die unüberwachte Anpassung an neue Domänen.
Eine weitere Herausforderung ist, dass Deep-Learning-Modelle mit nur wenigen Trainingsdaten in offenen Szenarien ihre Grenzen und Unsicherheiten erkennen müssen.
Deshalb entwickeln wir Modelle, die selbst unter Unsicherheit fundierte Entscheidungen treffen und ihre Unsicherheit präzise angeben. Das erhöht die Systemsicherheit und verbessert die Generalisierung über die Trainingsdaten hinaus.
Ein Praxisbeispiel aus dem Automotive-Bereich: Deep-Learning-Modelle, die Sensorsysteme steuern, müssen auch bei ungewöhnlichem Wetter oder seltenen Objekten zuverlässig funktionieren.
Use Case
Synthetische Daten: Generieren und gezielt erweitern
-

Um Sicherheit zu gewährleisten, muss ein in der Produktion eingesetztes Modell gut über verschiedene Szenarien hinweg generalisieren und robust gegenüber verschiedenen Grenzfällen sein. Um dies zu ermöglichen, müssen diese seltenen Fälle ausreichend in den Trainingsdaten vorhanden sein.
Einführung
KI-Modelle erreichen ihre volle Leistungsfähigkeit, wenn sie auch in seltenen Szenarien und unter außergewöhnlichen Bedingungen zuverlässig arbeiten. Solche Daten sind in realen Aufzeichnungen jedoch oft rar und teuer zu beschaffen. Generative Verfahren wie Generative Adversarial Networks (GANs) oder Diffusionsmodelle eröffnen hier neue Möglichkeiten: Sie erzeugen synthetische Daten, die realistisch wirken und gezielt Lücken schließen.
Wir entwickeln dafür hochleistungsfähige Datensynthese-Modelle mit drei Zielen:
- Kosten senken: Reduzierung des Aufwands für Erfassung und Annotation durch synthetische Erweiterung bestehender Datensätze.
- Realitätsniveau steigern: Generierung realitätsnaher Daten mit besonderem Fokus auf seltene und unterrepräsentierte Szenarien.
- Robustheit erhöhen: Verbesserung der Gesamtleistung und Widerstandsfähigkeit nachgelagerter Modelle durch den gezielten Einsatz synthetischer Daten.
-

Von unserem OASIS-Modell synthetisierte Bilder durch Manipulation latenter Richtungen, die Tag-zu-Nacht und bewölkt-zu-regnerisch Szeneneigenschaften entsprechen.
Unsere Forschung
Zusätzliche Daten im Loop
Reduzierte Kosten
Synthetische Datengenerierung senken Aufwand und Kosten für Erfassung und Annotation. Große Mengen hochwertiger Trainingsdaten lassen sich automatisiert erzeugen und zur Leistungssteigerung nachgelagerter Modelle einsetzen.
Effizienz bei knappen Daten
Die Algorithmen sind auf Szenarien mit wenigen Trainingsbeispielen optimiert. Synthetische Daten erweitern diese Proben durch anspruchsvolle Transformationen und verbessern die Modellleistung.
Höhere Robustheit
Die Verfahren erzeugen realistische Ausreißer, Randfälle und unterrepräsentierte Beispiele. Solche Daten sind entscheidend für robuste Modelle, in realen Datensätzen jedoch schwer zugänglich.
Kontinuierliche Weiterentwicklung
Das Forschungsteam entwickelt laufend neue Methoden zur Datensynthese, publiziert in führenden Fachjournalen und testet die Ansätze in zahlreichen Bosch-Anwendungen
Referenzen
Zhang, D., & Khoreva, A. (2019). Progressive Augmentation of GANs. NeurIPS. [PDF] [Code]
Schoenfeld, E., Schiele, B., & Khoreva, A. (2020). A U-Net Based Discriminator for Generative Adversarial Networks. CVPR. [PDF] [Code] [Video]
Schoenfeld, E., Sushko, V., Zhang, D., Gall, J., Schiele, B., Khoreva, A. (2021). You Only Need Adversarial Supervision for Semantic Image Synthesis. ICLR. [PDF] [Code] [Video]
Sushko, V., Gall, J., Khoreva, A. (2021). One-Shot GAN: Learning to Generate Samples from Single Images and Videos. CVPR Workshops. [PDF] [Code] [Video]
Erklärbare und robustes DL

Intelligente autonome Systeme müssen ihre Umgebung verstehen – auch dann, wenn sich diese im Laufe der Zeit verändert und anders aussieht als zuvor. Ein klares Verständnis darüber, wie und wann die Systeme zuverlässig und robust arbeiten, stärkt zudem das Vertrauen der Nutzenden.
Unser Schwerpunkt liegt auf der Entwicklung Deep-Learning-basierter Ansätze für komplexe Wahrnehmungsaufgaben. Dazu zählt etwa die Multitask-Wahrnehmung, bei der ein einziges neuronales Netzwerk mehrere Objekterkennungs- und semantische Segmentierungsaufgaben gleichzeitig übernimmt. Darüber hinaus entwickeln wir Verfahren, die Objekte zeitweise verfolgen und sie mithilfe mehrerer Perspektiven präzise in 3D lokalisieren.
Neben leistungsstarken Lösungen für Wahrnehmungsprobleme entwickeln wir auch Werkzeuge zur Quantifizierung und Verbesserung der Robustheit, Erklärbarkeit und Kalibrierung neuronaler Netze.
Hauptanwendungsfelder unserer Wahrnehmungssysteme sind Fahrerassistenz, automatisiertes Fahren und Videoüberwachung.
Use Case
Deep Learning für zeitliche und Multi-View-Datenfusion
-
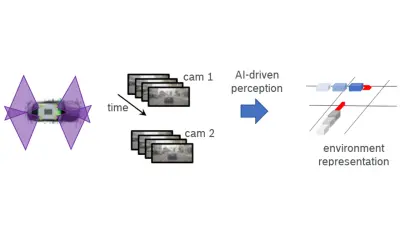
Ein Fahrzeug, das mit mehreren Kameras ausgestattet ist (links, Sichtfelder in Violett), erzeugt eine zeitliche Sequenz von Einzelkamera-Bildern (Mitte). Wir forschen an KI-gesteuerten Wahrnehmungsfunktionalitäten zur Generierung einer Umgebungsrepräsentation, die beispielsweise Informationen über Fahrzeugpositionen und -bewegungen abdeckt (rechts).
Einführung
Viele intelligente Systeme erfassen ihre Umgebung mit Sensoren wie RGB-Kameras. Das Entwerfen und Trainieren „tiefer neuronaler Netze“ (DNNs) für Wahrnehmungsaufgaben ist herausfordernd:
- Fusion heterogener Sensordaten für ein vollständiges Szenenverständnis.
- Integration zeitlicher Informationen zur Objektverfolgung und Bewegungsschätzung.
- Begrenzte Architekturgröße in Embedded Systems durch Latenz, Energieverbrauch und Hardwarekosten.
Unsere Antwort sind neuronale Architekturen für die Multitask-Wahrnehmung. Sie bündeln mehrere Aufgaben in einem Netzwerk und reduzieren den Rechenaufwand. Erweiterungen um Multi-View- und Zeitfusion ermöglichen eine konsistente 3D-Repräsentation der Umgebung und die robuste Verfolgung beweglicher Objekte.
Zentral bleibt zudem die Frage nach Zuverlässigkeit in sicherheitskritischen Anwendungen:
- Nachvollziehbarkeit der internen Datenverarbeitung zur Vertrauensbildung.
- Robustheit gegenüber Domänenverschiebungen und Grenzfällen.
- Verlässliche Konfidenzaussagen zu Vorhersagen.
- Validierungsmethoden für den Einsatz in sicherheitskritischen Szenarien.
Ziel ist die Entwicklung von Werkzeugen, die den Stand der Technik in der Deep-Learning-basierten Wahrnehmung voranbringen – und die Basis für leistungsfähige, robuste und vertrauenswürdige KI-Systeme schaffen.
Unsere Forschung
Multitask-Wahrnehmung
Ein gemeinsames Netzwerk kann mehrere Aufgaben gleichzeitig bearbeiten – etwa Objekterkennung, semantische Segmentierung oder optische Flussabschätzung. Ein geteilter Backbone reduziert den Hardwarebedarf und senkt die Latenz.
Zeitliche und Multi-View-Wahrnehmung
Dynamische Szenen lassen sich mit einem einzelnen Bild kaum vollständig erfassen. Die Kombination zeitlicher Informationen und mehrerer Sensoransichten ermöglicht ein deutlich präziseres Verständnis der 3D-Umgebung.
Robustheit
Neuronale Netze müssen auch bei abweichenden Eingaben zuverlässig arbeiten – etwa bei Domänenverschiebungen oder manipulierten Daten. Dafür entwickeln wir Architekturen, Trainingsverfahren und Zertifizierungsmethoden für robuste Wahrnehmungssysteme.
Interpretierbarkeit und Validierung
Für sicherheitskritische Anwendungen ist Transparenz unverzichtbar. Es gilt zu verstehen, wie neuronale Netze arbeiten, und sicherzustellen, dass keine fehlerhaften Korrelationen Robustheit oder Fairness gefährden. Hierfür entwickeln wir geeignete Methoden und Ansätze.
-
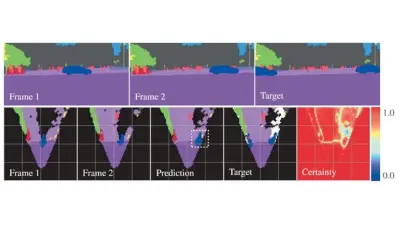
Gezeigt wird eine Sequenz semantischer Segmentierungen (oben) und zugehöriger semantischer Gitter (unten, schwarze Bereiche entsprechen unbekannten Teilen). Basierend auf Frame 1 und 2 wird eine Vorhersage des semantischen Gitters und der zugehörigen Unsicherheit generiert und mit einem Zielwert verglichen.
Referenzen
Eulig, E., Saranrittichai, P., Mummadi, C., Rambach, K., Beluch, W., Shi, X., & Fischer, V. (2021). DiagViB-6: A Diagnostic Benchmark Suite for Vision Models in the Presence of Shortcut and Generalization Opportunities. IEEE/CVF (ICCV). [PDF][Code]
Fuchs, F., Worrall, D., Fischer, V., & Welling, M. (2020). SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks. NeurIPS. [PDF] [Code] [Video]
Mummadi, C., Subramaniam, R., Hutmacher, R., Vitay, J., Fischer, V., & Metzen J. (2021). Does enhanced shape bias improve neural network robustness to common corruptions? ICLR. [PDF] [Video]
Mummadi, C., Hutmacher, R., Rambach, K., Levinkov, E., Brox, T., & Metzen J. (2021). Test-Time Adaptation to Distribution Shift by Confidence Maximization and Input Transformation. arXiv. [PDF]
Wong, E., Schneider, T., Schmitt, J., Schmidt, F. R., Kolter, J. Z. (2020). Neural Network Virtual Sensors for Fuel Injection Quantities with Provable Performance Specifications (IEEE IV). [PDF]
Wong, E., Schmidt, F. R., Kolter, J. Z. (2019). Wasserstein Adversarial Examples via Projected Sinkhorn Iterations (ICML). [PDF]
Wong, E., Schmidt, F. R., Metzen, J. H., Kolter, J. Z. (2018). Scaling Provable Adversarial Defenses. In Neural Information Processing Systems (NeurIPS). [PDF]